
想不到吧,emoji也可以说出来 [打字系列Vol.5]
这是打字系列的第四篇文章,介绍一下自己的工作!
大家可能都用过语音输入来打字,但是除了文字,表情是不是也可以用语音说出来呢?
# 一句话总结
许多人会在不方便的时候使用语音输入法。Voicemoji 可以让用户通过说关键词的方式来输入表情,来帮助视障以及运动障碍的用户更方便地使用emoji。
目录
谁会用到语音输入
视障用户会用emoji吗
Voicemoji:把emoji说出来
硬核时刻:emoji 预测
谁会用到语音输入
语音输入,又名听写,也就是通过说话来打字的输入方式,可以通过键盘上的话筒按钮激活。日常生活中你可能很少用到它,毕竟在公共场合下说”哈哈xswl“还是很羞耻的。然而当你走路,骑车,开车,或者懒得打字的时候,就会情不自禁的点击那个小话筒。相比与打字,听写的方式更像是一种锦上添花的点缀。
然而对于另一群用户而言,语音输入不可或缺。例如视力障碍用户由于看不清键盘,经常会用语音输入来打字;运动障碍(比如无法使用双手)的用户更是要依赖语音来进行各种操作。老年人,比如我们的长辈,也可能因为不熟练拼音或者键盘而使用手写或者语音——总而言之,语音输入是一种非常重要的输入方式。
另外,如果你在和男/女朋友吃饭,收发信息时用语音输入也可以证明自己的清白(大误。
视障用户会用emoji吗
我在做这个项目的时候,主要是调研了视障用户的群体。既然我们的目的是可以用语音输入emoji,那么第一个要回答的问题就是:视障用户会用emoji吗?因为emoji属于表情,表情是用来看的。如果他们压根不用,那”语音输入表情“也就是个伪需求了。
通过我们的采访,发现视障用户不仅会用emoji,而且还会斗图!我们发现大部分用户每天不仅会收到别人发来的表情,而且自己也会使用emoji。然而他们大都只发十个左右常用的表情,例如 (微笑),♥(爱心), (笑哭), (感谢)这些意义明确的emoji,而很少用到其他例如 (老子) (小丑竟然是我自己)这种含义奇怪的表情,很大一部分原因是,他们根本不知道有这些emoji。
到今天为止,已经有三千多个emoji被设计出来,这个数字每年都在增长。我们在输入emoji的时候,会进入一个类似列表一样的界面,几十个emoji排成排,大眼一扫就能知道选择哪一个。键盘也会对这些表情进行分类,来方便查找。
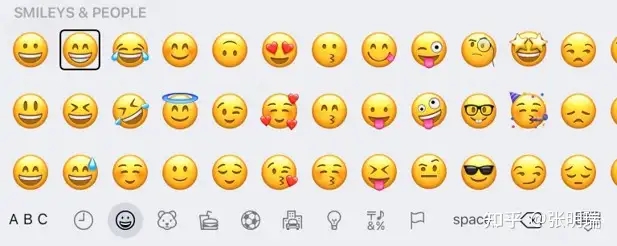
这种设计,对于使用读屏软件的视障用户来讲,简直是灾难。因为读屏软件每次只能读一个emoji的描述,他们需要不断地在屏幕上进行滑动来一个一个地听,直到找到想要的那个。对于常用的熟悉了位置的emoji还好,但是对于另外几千个乱七八糟的emoji来讲,找到它们往往要花上几分钟甚至十几分钟,最后经常因为找不到只好作罢。
另外一个小提示,虽然视障用户也会发表情包,但读屏软件对于gif这种会动的表情支持并不友好,因此如果你和他们聊天,请尽量避免发送动图哦。
Voicemoji:把emoji说出来
铛铛铛!展示我的工作——Voicemoji [1] 的时刻到了!Voicemoji是一个能够让用户用语音输入emoji的系统,废话不说,先看展示:(不好意思没做中文。。。

Voicemoji通过识别关键字来输入表情,比如当用户说“给我一个下雪的表情”时,Voicemoji会识别到“给我一个”和“表情”这两个关键词,然后就把中间的描述“下雪”来转换成emoji。听起来是不是很自然?比如你也可以说“给我一个小丑竟然是我自己的表情”来获得一个 ,再也不用花十几分钟去表情键盘里找了!Voicemoji,用语音来输入emoji_哔哩哔哩 (゜-゜)つロ 干杯~-bilibiliVoicemoji通过识别关键字来输入表情,比如当用户说“给我一个下雪的表情”时,Voicemoji会识别到“给我一个”和“表情”这两个关键词,然后就把中间的描述“下雪”来转换成emoji。听起来是不是很自然?比如你也可以说“给我一个小丑竟然是我自己的表情”来获得一个 ,再也不用花十几分钟去表情键盘里找了!
在提供关键词搜索表情的功能以外,Voicemoji也会根据说话的内容来推荐表情。比如你说了“今天中午我吃了牛肉面”,虽然没有明确要输入某个emoji,但是Voicemoji会返回和这句话相关的一些表情,例如 。对于视障用户的好处是,这种推荐会让他们了解有哪些新的表情可以使用,从而不仅仅只用到最常用的那些emoji(推荐的机制详情请移步硬核时刻)。
在实验中我们找到了来自中国和美国两地的视障用户来使用Voicemoji,发现用语音输入表情(平均耗时4.7秒)要比用传统的键盘方式(平均耗时53.7秒)快了十倍以上!而且大家发现表情推荐的功能很好用,让他们学会了许多以前不熟悉的emoji。
硬核时刻:emoji 预测
这里是硬核一点的知识,面向想要进一步了解的同学们:)
Voicemoji 会通过所说的内容来预测相关的 emoji。这是怎么做到的呢?预测的技术涉及到NLP(自然语言处理)中的embedding(词向量)。通俗一点来讲,就是用数学中向量的方式来表示每一个单词,这样就可以通过一些计算,例如向量求和,求夹角,来找到和某一个词类似的其他词汇。
预测 emoji 也就是先通过把 emoji 向量化,然后找到和 所说内容最接近的 emoji 向量。最常用的词向量技术是使用深度学习的模型,例如word2vec。Voicemoji 中用到的模型来源于 Deepmoji [2],感兴趣的同学可以去读一读原paper。

————————————————————
Voicemoji 不仅仅是针对视障用户设计的,更重要的是,它提供了一种不用打字也能输入非文字信息的思路。当然,除了emoji以外,许多动图、表情因为没有规范的描述,依然缺乏有效的输入方式。也希望如果有做输入法的大厂们看到了这篇文章,可以考虑一下在自己的产品中加上语音输入emoji的功能,嘿嘿。
本文引用 [1] Mingrui ``Ray'' Zhang, Ruolin Wang, Xuhai Xu, Qisheng Li, Ather Sharif, Jacob O. Wobbrock: Voicemoji: Emoji Entry Using Voice for Visually Impaired People, 2021 [2] Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, Sune Lehmann: Using millions of emoji occurrences to learn any-domain representationsfor detecting sentiment, emotion and sarcasm, 2016 [3] Instagram Engineering: https://instagram-engineering.com
最后更新于